
자료구조 Data Structure
1) 배열
배열은 삽입, 삭제가 느리고 조회가 빠르다
2) 연결리스트
배열과 연결리스트는 특징이 반대인데 파이썬에서는 배열의 기호로 [] (리스트)를 사용하여 헷갈릴 수가 있음.
연결리스트는 노드 단위로 존재. 삽입, 삭제가 빠르고 조회가 느림.
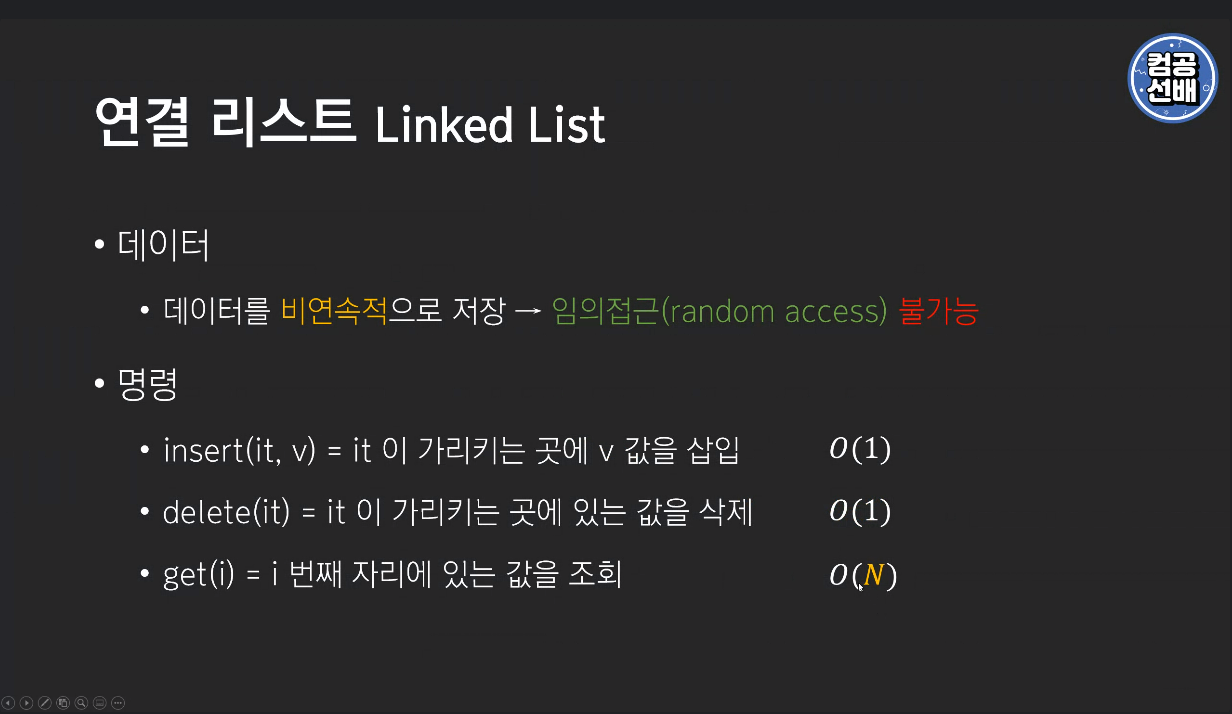
파이썬은 연결리스트가 없어 직접 구현해야 한다고 함.
연결리스트는 데이터를 비연속적으로 저장하여 임의 접근이 불가능!!
3) 스택
LIFO / FILO 구조
배열은 스택의 연산을 포함하고 있다. => 배열 ) 스택
배열을 이용해서 스택을 구현. 한가지 주의점은 배열에서 스택을 구현할 때, pop()에 인덱스를 주어서 맨 위가 아닌 값을 삭제하게 되면 스택으로써의 기능(?)을 잃게되어 적절하지 않은 상황이 됨. 스택으로 쓸거면 중간 값들은 건드리면 안됨.
4) 큐
LILO / FIFO 구조
파이썬에서 큐를 쓰고 싶으면 import queue 대신 from collections import deque(덱)를 씀.
* 덱
Double-Ended QUEue의 줄임말로, '양면 큐'를 의미하여 앞뒤로 입출력이 다 가능함. 큐의 연산을 포함하고 있으므로 덱 ) 큐 가 되므로 큐를 쓰고 싶으면 덱을 쓰면 되는 것임.
큐와 같이 append를 쓰면 맨 뒤에 값이 추가되는데, 앞으로 넣고 싶으면 appendLeft를 쓰면 됨.(Left를 앞으로 봄)
pop도 마찬가지로 맨 뒤 값이 빠지고, popLeft를 쓰면 맨 앞에 값이 빠짐.
5) 우선순위 큐
노드에 어떤 것이든 담을 수 있다. 단, 노드 간에 우선순위가 존재해야 한다 = 정렬이 가능해야 한다.
내부적으로 힙(Heap)이라는 자료구조를 써서 구현됨. 힙은 완전이진트리 형태로 이루어져 있다. 트리에서 최상단 노드는 루트 노드로, 우선 순위가 가장 높다.

최대 힙 : 값이 클수록 우선 순위가 높다.
최소 힙 : 값이 작을수록 우선 순위가 높다.
-> 이에 따라서 값을 예를 들어 삽입을 하면 루트 노드쪽으로 가면서 위치를 바꿈(switch)

파이썬에서 우선순위 큐를 쓰려면 import heapq를 사용!
heapq.heappush() -> 삽입
heapq.heappop() -> 삭제
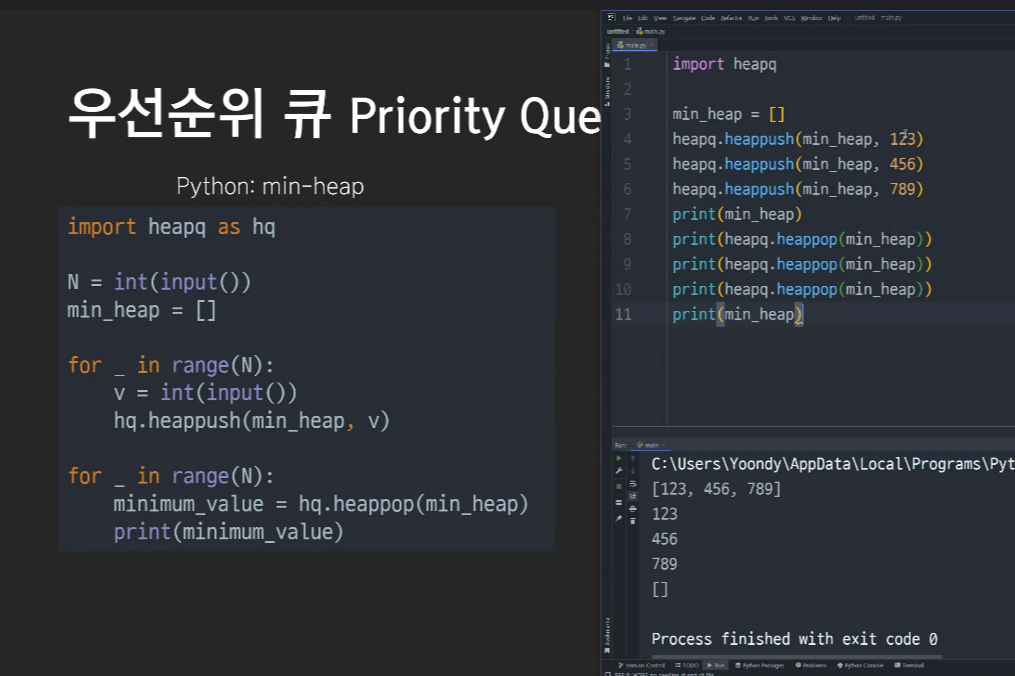
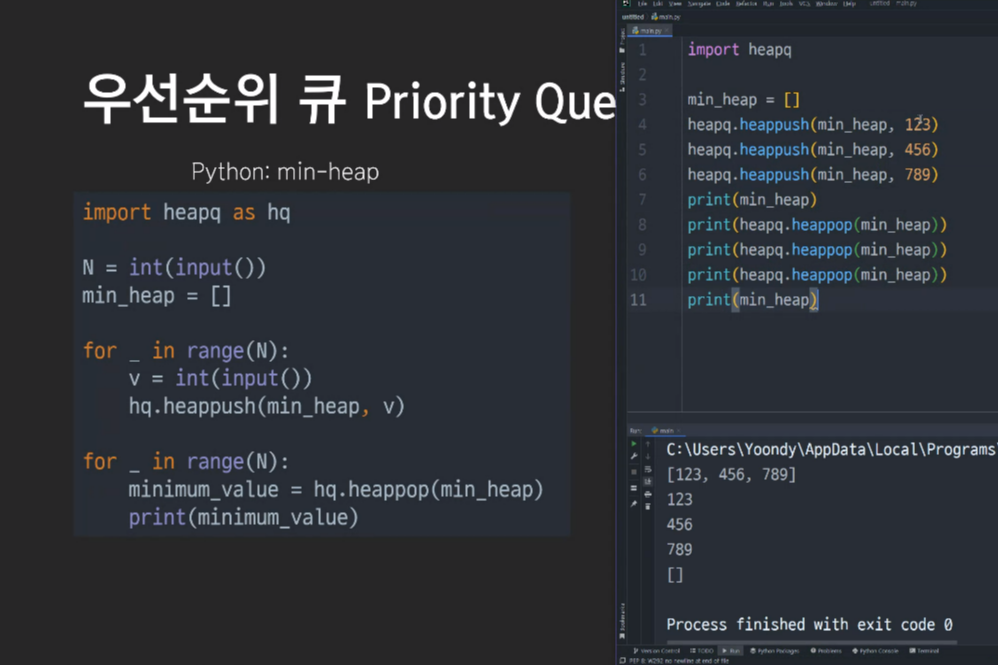
=> 힙정렬의 시간복잡도는 O(NlogN)이 됨. (2 * N * logN = 2NlogN, O(2NlogN) = O(NlogN).)
파이썬에서는 기본이 min-heap이다. (max-heap은 없음)
그럼 최대힙이 필요할 때는 ?!
넣기 전에 부호를 -로 바꿔서 넣고, 뺀 다음에 다시 바꿔주면 뒤집힘!
6) 맵
가장 큰 특징 : key-value 쌍으로 데이터를 저장
파이썬에서는 딕셔너리를 사용

해시를 이용해서 구현된 맵의 특징 :
맵에 들어간 원소는 순서가 보장되지 않음. => 데이터를 넣은 순서대로 이루어지지 않는다.
내부적으로 해시 테이블이라는 자료구조를 써서 구현됨. => O(1)이라도 데이터가 너무 많으면 느릴 수 있다.
파이썬에서는 {}를 사용 (딕셔너리)
7) 집합 Set
데이터들을 중복하지 않고 저장
파이썬에서는 기본 연산으로 교집합, 합집합, 차집합 등 지원
삽입, 삭제, 조회 전부 O(1)
맵처럼 내부가 hash로 되어 있어 특징도 맵이랑 똑같음. (해시의 특징이기 때문)
'알고리즘' 카테고리의 다른 글
| [프로그래머스/JS] 기사단원의 무기 (0) | 2024.11.26 |
|---|---|
| [프로그래머스/JS] 문자열 내 p와 y의 개수 - JavaScript 문자열 내 특정 문자의 개수 찾기 (1) | 2024.09.03 |
| 다이나믹 프로그래밍(DP, 동적 계획법)의 특징 / DP 알고리즘 문제 접근법 (1) | 2024.01.05 |
| 그래프 탐색 알고리즘 DFS/BFS 차이점 및 특징 (0) | 2023.04.13 |